对于正数 x 来说, 左移 n 位<<相当于 x * 2^n, 右移 n 位>>相当于 x mod 2^n,取余 无符号右移 n 位 >>>相当于 x mod 2^n,取余
对负数 y 来说, 左移 n 位<<相当于 y * 2^n, 右移 n 位>>相当于
HashMap 的基本原理
源码解读
全局变量
DEFAULT_INITIAL_CAPACITY
1 2 3 4 5 6 7
/** * The default initial capacity - MUST be a power of two. * 默认初始化容量,必须是2的幂 */ static final int DEFAULT_INITIAL_CAPACITY = 4;//JDK7 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //即16 JDK8
MAXIMUM_CAPACITY
1 2 3 4 5 6 7 8
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. * 最大的容量,必须是2的幂,并且在 [2,2^30]之间 * int 型的最大值为 2^31 -1 ,但 HashMap 的容量必须是 2 的幂,所以最大值只能是 2^30 */ static final int MAXIMUM_CAPACITY = 1 << 30;
DEFAULT_LOAD_FACTOR
1 2 3 4 5
/** * The load factor used when none specified in constructor. * 默认的负载因子值,用来计算扩容的临界值,0.75f */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
EMPTY_TABLE
1 2 3 4 5
/** * An empty table instance to share when the table is not inflated. * 当 table 还没扩容时的实例,即一个空的table */ static final HashMapEntry<?,?>[] EMPTY_TABLE = {};
table ;HashMap 中的存放键值对的单链表数组
1 2 3 4 5
/** * The table, resized as necessary. Length MUST Always be a power of two. * 可以随时调整的 table,长度必须是2的幂 */ transient HashMapEntry<K,V>[] table = (HashMapEntry<K,V>[]) EMPTY_TABLE;
size
1 2 3 4 5
/** * The number of key-value mappings contained in this map. * 这个 map 中键值对的数量 */ transient int size;
threshold
1 2 3 4 5 6 7 8 9
/** * The next size value at which to resize (capacity * load factor). * 下一次进行扩容的值,即阈值,等于最大容量 * 负载因子 * @serial */ // If table == EMPTY_TABLE then this is the initial capacity at which the // table will be created when inflated. //如果 table 是空的时候,即 table == EMPTY_TABLE , threshold 的值就是 table 扩容时的初始容量 int threshold;
loadFactor
1 2 3 4 5 6 7 8 9
/** * The load factor for the hash table. * hash table 的负载因子 * @serial */ // Android-Note: We always use a load factor of 0.75 and ignore any explicitly // selected values. //Android-Note: 使用 0.75 这个固定的值,忽略其他明确的值 final float loadFactor = DEFAULT_LOAD_FACTOR;
/** * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and load factor. * * @param initialCapacity the initial capacity * @param loadFactor the load factor * @throws IllegalArgumentException if the initial capacity is negative * or the load factor is nonpositive */ publicHashMap(int initialCapacity, float loadFactor){ if (initialCapacity < 0) thrownew IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) { initialCapacity = MAXIMUM_CAPACITY; } elseif (initialCapacity < DEFAULT_INITIAL_CAPACITY) { initialCapacity = DEFAULT_INITIAL_CAPACITY; }
if (loadFactor <= 0 || Float.isNaN(loadFactor)) thrownew IllegalArgumentException("Illegal load factor: " + loadFactor); // Android-Note: We always use the default load factor of 0.75f.
// This might appear wrong but it's just awkward design. We always call // inflateTable() when table == EMPTY_TABLE. That method will take "threshold" // to mean "capacity" and then replace it with the real threshold (i.e, multiplied with // the load factor). threshold = initialCapacity; init(); }
/** * 扩容 table ,toSize 是要扩大到的容量 */ privatevoidinflateTable(int toSize){ // Find a power of 2 >= toSize //计算 table 的容量,因为必须是2的幂,所以通过 roundUpToPowerOf2() 方法计算出大于等于 toSize 值的 2的幂 int capacity = roundUpToPowerOf2(toSize);
// Android-changed: Replace usage of Math.min() here because this method is // called from the <clinit> of runtime, at which point the native libraries // needed by Float.* might not be loaded. //再计算新的阈值,即 table 容量 * 负载因子,如果超过了最大的容量,则将阈值设置为 table 最大值 + 1 float thresholdFloat = capacity * loadFactor; if (thresholdFloat > MAXIMUM_CAPACITY + 1) { thresholdFloat = MAXIMUM_CAPACITY + 1; }
/** * Offloaded version of put for null keys */ private V putForNullKey(V value){ //取出数组中索引为 0 的链表,进行循环, for (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) { //如果链表中有 key 为 null 的键值对,即该 HashMap 中有 key 为 null 的键值对,则将新值替换旧值,并返回旧值。 if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } //如果原来链表中没有 key 为 null 的键值对,将 modCount 自增 modCount++; //并向链表中添加一个键值对 addEntry(0, null, value, 0); //返回 null returnnull; }
③ 再看计算索引的方法 indexFor(int hash, int length) hash -> hash 值 length -> 数组长度
1 2 3 4 5 6 7 8
/** * Returns index for hash code h. */ staticintindexFor(int h, int length){ // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; //即相当于 h % length,取余数 return h & (length-1); }
④ 接着看 addEntry(int hash, K key, V value, int bucketIndex) 方法 这个方法有四个入参分别是
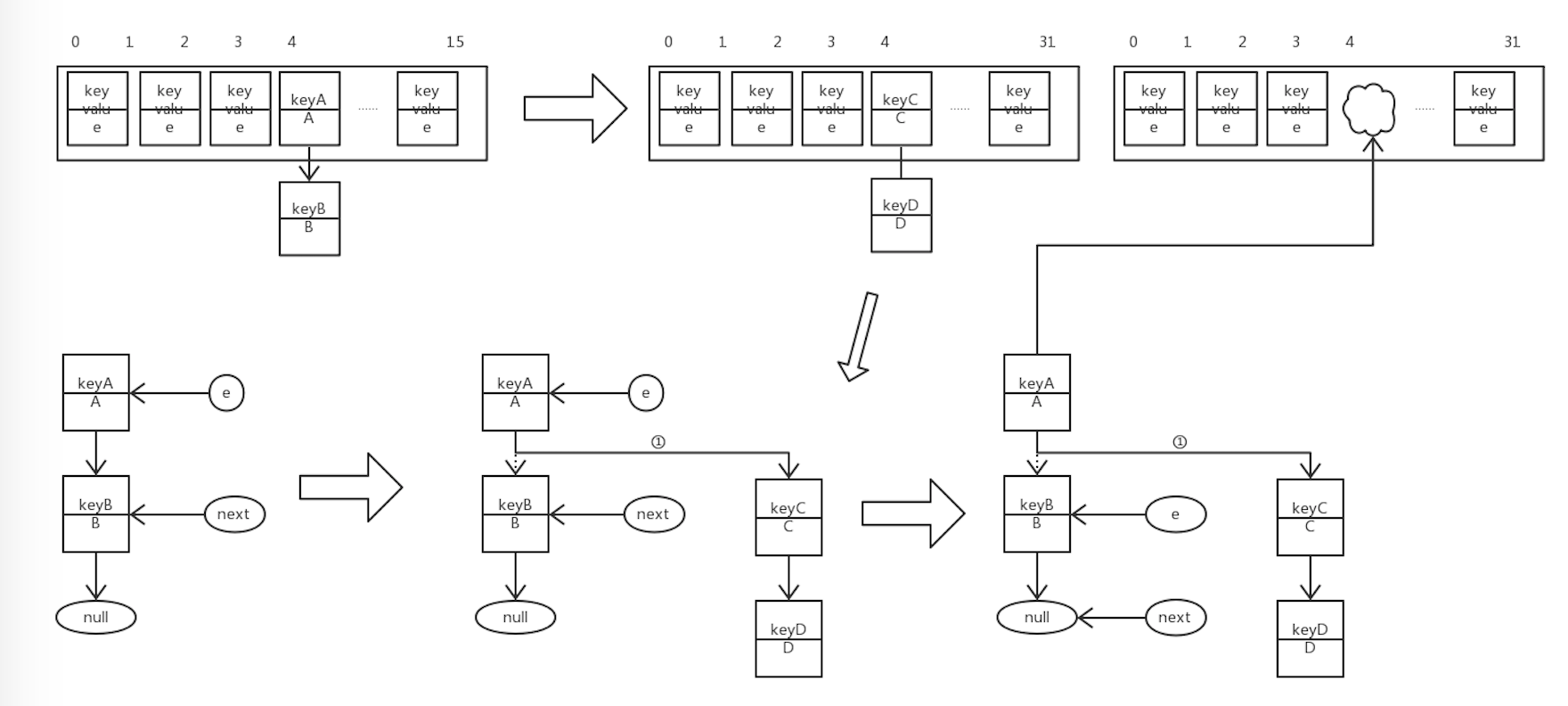
voidtransfer(HashMapEntry[] newTable){ //计算新的 table 的容量 int newCapacity = newTable.length; //对旧的 table 数组进行循环 for (HashMapEntry<K,V> e : table) { //下面对链表进行循环 while(null != e) { HashMapEntry<K,V> next = e.next; //计算当前节点在新 table 中的索引值 int i = indexFor(e.hash, newCapacity); //取新的 table 中第i个位置的链表中第一个键值对,赋值给 e.next e.next = newTable[i];//① //将当前的 键值对 放入新 table 的第一个位置 newTable[i] = e;//② //将原来的链表上的下一个节点赋值给 e e = next; } } }
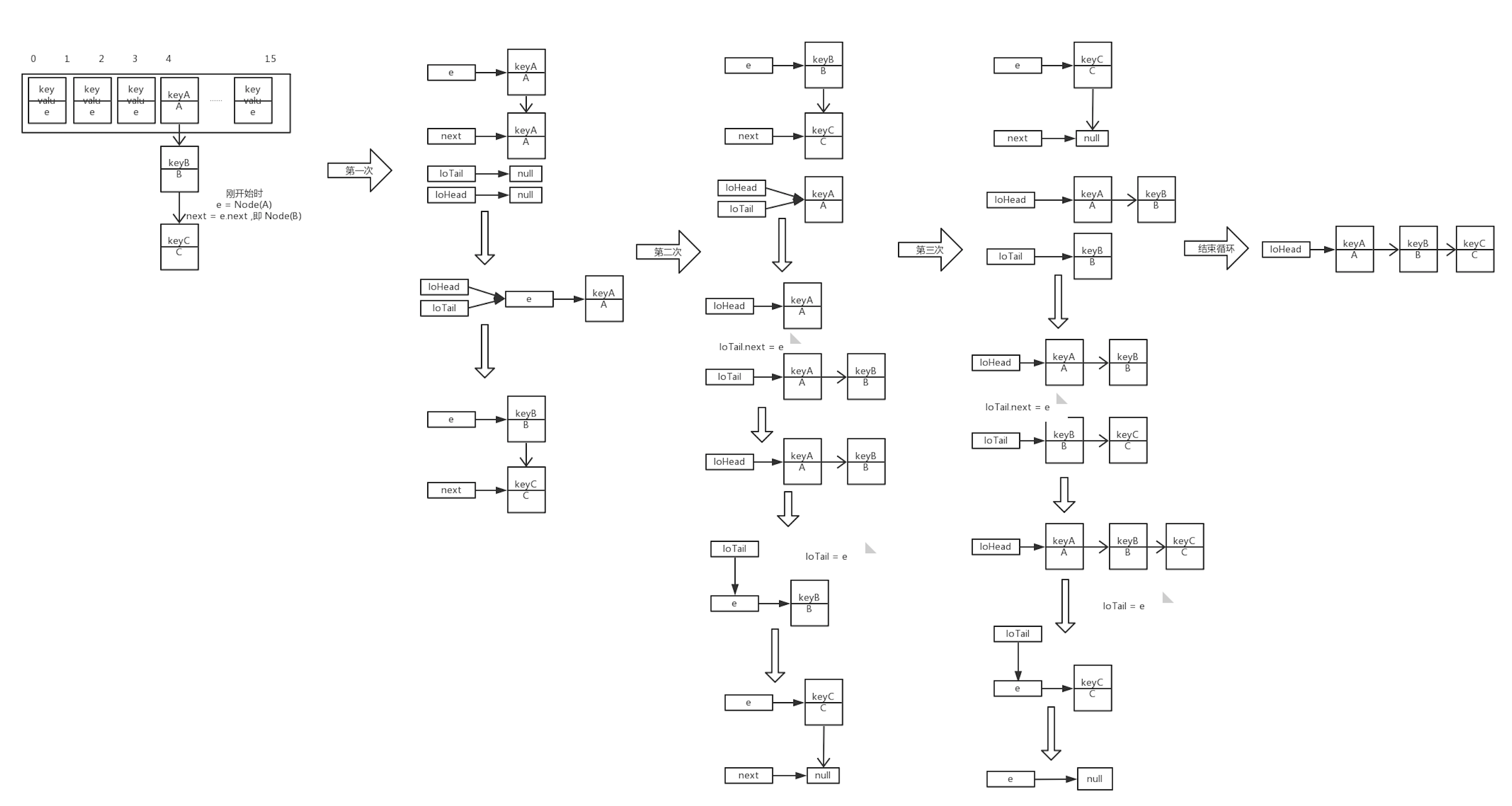
图解
在 for 循环时,e 指向旧 table 数组中的某条链表
第一次循环时,e 指向该链表的第一个键值对,next 指向 e.next 即第二个键值对
PS.我们假设转移前后我们的这两个键值对的 hash 值计算出来的索引仍然相同
将新 table 数组第 i 个位置的链表接到 e 的后面,再把 e 放到 newTable[i] 的位置
将 next 赋值给 e ,继续循环,直到链表循环结束
⑥ createEntry(int hash, K key, V value, int bucketIndex) 创建新的键值对
新插入的键值对会插入到链表最前面
1 2 3 4 5 6 7 8 9
voidcreateEntry(int hash, K key, V value, int bucketIndex){ //将该键值对对应的索引的位置的键值对table[bucketIndex] 的引用赋值给局部变量 e HashMapEntry<K,V> e = table[bucketIndex]; //新建一个键值对,即新放入的 hash,key,value,该键值对的 next 是原来的在这个索引位置的键值对 //可见插入键值对时会插入到链表的最前面 table[bucketIndex] = new HashMapEntry<>(hash, key, value, e);⑦ //对 size 自增,即键值对数量 + 1 size++; }
⑦ HashMapEntry 构造方法,可见传入的第四个参数 n 会被放到这个新的 entry 的 next ,即放到第四个参数在链表位置上的前面。
1 2 3 4 5 6
HashMapEntry(int h, K k, V v, HashMapEntry<K,V> n) { value = v; next = n; key = k; hash = h; }
/** * Initializes or doubles table size. If null, allocates in * accord with initial capacity target held in field threshold. * Otherwise, because we are using power-of-two expansion, the * elements from each bin must either stay at same index, or move * with a power of two offset in the new table. * * @return the table */ final Node<K,V>[] resize() { //获取旧的数组引用 Node<K,V>[] oldTab = table; //计算旧数据的长度 int oldCap = (oldTab == null) ? 0 : oldTab.length; //获取旧阈值 int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { //如果旧数组长度大于等于最大容量,则直接返回旧数组 threshold = Integer.MAX_VALUE; return oldTab; } elseif ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) //新数据容量 = 旧数据容量左移一位,即 * 2 //如果新数组容量小于最大值,且旧数组容量大于等于默认长度(16) //同时将阈值扩大一倍 newThr = oldThr << 1; // double threshold } elseif (oldThr > 0) // initial capacity was placed in threshold // 如果原来的 threshold 大于0则将容量设为原来的 threshold // 在第一次带参数初始化时候会有这种情况 newCap = oldThr; } else { // 在默认无参数初始化会有这种情况 newCap = DEFAULT_INITIAL_CAPACITY;//16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//16 * 0.75 = 12 } if (newThr == 0) { //如果新的阈值为 0 //计算新的阈值 float ft = (float)newCap * loadFactor; //如果新的容量小于最大容量且新的阈值也小于最大容量 //则新的阈值等于 ft ,否则设置为 Integer.MAX_VALUE newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); }